
Today’s practice question requires us to write a Python function that converts uppercase vowels to lowercase.
Here are some concepts we’ll discuss in the post:
- How to convert lowercase characters to uppercase in Python
- How to use the
lower()function - What is the Unicode standard
- What are hexadecimal numbers
- How to use the
ord()andchr()functions in Python
Table of Contents
Key Concepts
Before we start on the task for today, let’s discuss two different ways to convert uppercase characters to lowercase in Python.
- The first relies on the built-in
lower()function in Python. - The second method converts each letter in the string to Unicode and uses that to convert the letter to lowercase.
Using the built-in lower() function
Let’s first look at the built-in lower() function. This function is very easy to use, its syntax is as follows:
string_to_convert.lower()
The function converts all uppercase characters in the string string_to_convert into lowercase characters and returns the new string. The original string is not changed.
Let’s look at an example:
msg1 = 'HeLLo'
msg2 = msg1.lower()
print(msg1)
print(msg2)
Here, we first declare a variable called msg1 with the value 'HeLLo'.
Next, on line 2, we use msg1 to call the lower() function. This function converts all the uppercase characters in msg1 to lowercase and returns the new string, which we store in a variable called msg2.
Finally, we use two print statements to print the values of msg1 and msg2.
If you run the code above, you’ll get
HeLLo
hello
as the output. Straightforward? Good.
Using Unicode
Besides using the built-in lower() function to convert a string to lowercase, we can also use Unicode to convert lowercase characters to uppercase. This gives us more flexibility. For instance, we may only want to convert certain letters in a string to lowercase. If we use the built-in lower() function, all uppercase characters will be converted to lowercase. If we do not want that to happen, we can do the conversion ourselves.
To do that, we need to first understand the Unicode standard.
What is Unicode?
Unicode is a universal standard for encoding characters and symbols. It does that by assigning a code point to every character and symbol in every language in the world.
This means that even though a Chinese character is very different from an English letter, they can both be represented by a Unicode code point. For instance, the English letter ‘A’ is represented by the code point U+0041 while the Chinese character 我 is represented by U+6211.
About the Code Points
Let’s discuss the code point for the letter ‘A’. As mentioned above, the code point is U+0041.
U+ indicates that this is a Unicode code point while 0041 is a hexadecimal number assigned to ‘A’.
What is a hexadecimal number?
A hexadecimal number is a number that is represented in base 16.
Numbers can be represented in different bases. In everyday life, we represent numbers in base 10. This means that we use 10 digits (i.e. the digits 0 to 9) to represent our numbers. Each digit in a number is multiplied by a power of 10 to give us its actual value.
For instance, the number 327 stands for 3*102 + 2*101 + 7. The digit 3 represents the value 300, instead of simply the value 3.
When it comes to computers, we do not use base 10. Rather, we use base 2 (a.k.a. binary numbers) or base 16 (hexadecimal numbers).
The base 2 system uses only 2 digits – 0 and 1 – to represent numbers.
A number like 1101 stands for 1*23 + 1*22 + 0*21 + 1. In other words, the binary number 1101 becomes 13 when converted to base 10.
The base 16 system uses 16 digits and letters to represent numbers. The digits are 0 to 9, followed by the letters ‘A’ to ‘F’ (which represent numbers 10 to 15 respectively).
A number like AB7 stands for A*162 + B*161 + 7 = 10*162 + 11*16 + 7 = 2743.
If you convert 0041 to base-10 (decimal), you’ll get the number 65.
Got it?
If you have problems understanding how hexadecimal works, don’t worry. We do not really need to use them in this tutorial. What you need to know is simply that the hexadecimal number 0041 is the same as the decimal number 65.
Got it? Great.
Now, let’s return to our lowercase conversion problem.
Summary of Unicode Standard
Before proceeding, let’s do a quick summary of what the Unicode standard is. Here are two key points you need to know:
- All characters in every language can be represented by a Unicode code point
- The code point is given as a hexadecimal number
While the Unicode standard may be a bit confusing for beginners, the good news is that Python comes with two very useful built-in functions that help us work with the Unicode standard.
Python Functions – ord() and chr()
The first function is the ord() function. This function gives us the code point for every Unicode character. The best part is, it gives us the code point in decimal, so we do not have to worry about working with hexadecimal numbers. Let’s look at some examples:
print('Uppercase code points')
print(ord('A'))
print(ord('B'))
print(ord('Z'))
print('Lowercase code points')
print(ord('a'))
print(ord('b'))
print(ord('z'))
Here, we use the ord() function to get the code point (in decimal) for the letters ‘A’, ‘B’, ‘Z’, ‘a’, ‘b’ and ‘z’. If you run the code above, you’ll get the following output:
Uppercase code points
65
66
90
Lowercase code points
97
98
122
Straightforward? As you may have concluded from the output above, the code points for ‘A’ to ‘Z’ are the numbers 65 to 90. In contrast, the code points for ‘a’ to ‘z’ are the numbers 97 to 122. The code point for each individual letter is shown in the image below:
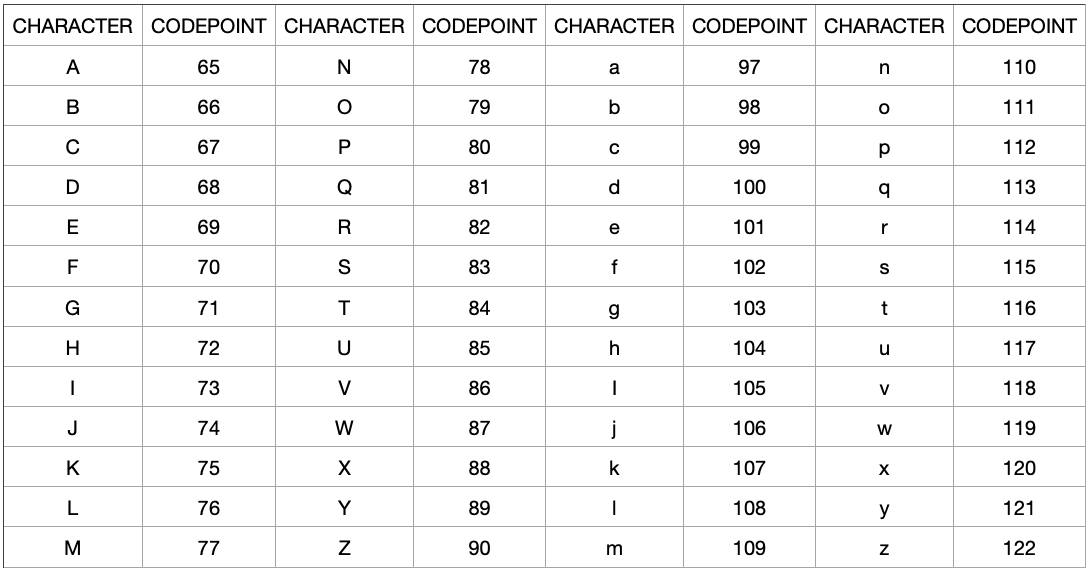
As you can see, we can get the code point for each lowercase letter by adding 32 to the code point of the corresponding uppercase letter.
For instance, to get the code point for ‘a’, we simply add 32 to the code point for ‘A’. In other words, we add 32 to 65. This gives us 97, which is the code point for ‘a’.
Does this give you an idea of how we can use Unicode code points to convert an uppercase letter to lowercase?
That’s right. To convert an uppercase letter to lowercase, we simply need to get its Unicode code point (using the ord() function) and add 32 to it. This gives us the code point for the lowercase letter.
Now the question becomes, how do we convert the code point for the lowercase letter back to a character?
To do that, we use another built-in function in Python – chr(). This function takes in a code point and returns the character for that code point. For instance, chr(97) gives us the character 'a'.
Got it? With this background knowledge, we are now ready to write a simple program to convert lowercase letters to uppercase. Here’s the program:
msg1 = 'HeLLo'
msg2 = ''
for i in msg1:
if ord(i) >= 65 and ord(i) <= 90:
i = chr(ord(i)+32)
msg2 = msg2 + i
print(msg1)
print(msg2)
Here, we first declare and initialize two variables msg1 and msg2. Next, we use a for loop (lines 4 to 7) to loop through the letters in msg1.
For each letter, we check if its Unicode code point is between 65 and 90 on line 5. If it is, we know that this is a uppercase character.
We then add 32 to the code point (ord(i) + 32) to get the code point for the equivalent lowercase character. We pass this result to the chr() function (chr(ord(i)+32)) and assign the result back to i on line 6.
Finally, on line 7, we concatenate i to msg2.
Next, after looping through all the letters in msg1, we exit the for loop and print the values of msg1 and msg2 on lines 9 and 10.
If you run the code above, you’ll get
HeLLo
hello
as the output. As you can see, all uppercase characters have been converted to lowercase. Clear?
Now that we know how to use Unicode to convert lowercase letters to uppercase, we are ready to work on our task for today.
Practice Question
Today’s task is to write a function called myLower() that accepts a string and converts all the uppercase vowels (‘A’, ‘E’, ‘I’, ‘O’, ‘U’) to lowercase.
Expected Results
To test your function, you can run the statements below:
print(myLower('AEIOU'))
print(myLower('BCDFGH'))
print(myLower('THIS IS A SIMPLE MESSAGE'))
you should get the following results:
aeiou
BCDFGH
THiS iS a SiMPLe MeSSaGe
Suggested Solution
Here’s the suggested solution for today’s practice question.
def myLower(msg):
msg2 = ''
for i in msg:
if ord(i) in (65, 69, 73, 79, 85):
i = chr(ord(i)+32)
msg2 = msg2 + i
return msg2
The solution above should be quite self-explanatory, except for line 4. On line 4, we use the Python keyword – in – to check if the result returned by the ord() function exists in the tuple (65, 69, 73, 79, 85). This tuple contains the Unicode code points for the characters ‘A’, ‘E’, ‘I’, ‘O’ and ‘U’.
For instance, if i equals ‘A’, ord(i) gives us the number 65.
ord(i) in (65, 69, 73, 79, 85)
is thus True and the if block (on line 5) gets executed. This block converts the uppercase ‘A’ to lowercase and assigns the result back to i.
On the other hand, if i equals ‘B’, ord(i) gives the number 66 which is not inside the tuple. The if block is thus not executed.
After the if block, we concatenate i with msg2 to form a new string on line 6.
After looping through all the letters in msg1 and concatenating i to form msg2, we return msg2 on line 7.
With that, the program is complete.